Storing Billions of VM Metrics with TimescaleDB

Originally published here.
With the recent launch of our Layerfile analytics project, we encountered a cool engineering problem - how to store billions of virtual machine (VM) metrics in PostgreSQL.
The problem
With the recent launch of our Layerfile analytics project, we encountered a cool engineering problem - how to store billions of virtual machine (VM) metrics in PostgreSQL. The metrics we wanted to track were the VM's CPU, disk and memory usage at a one second interval throughout the duration of its life. Our data can be considered time-series data as it is timestamped and append only.
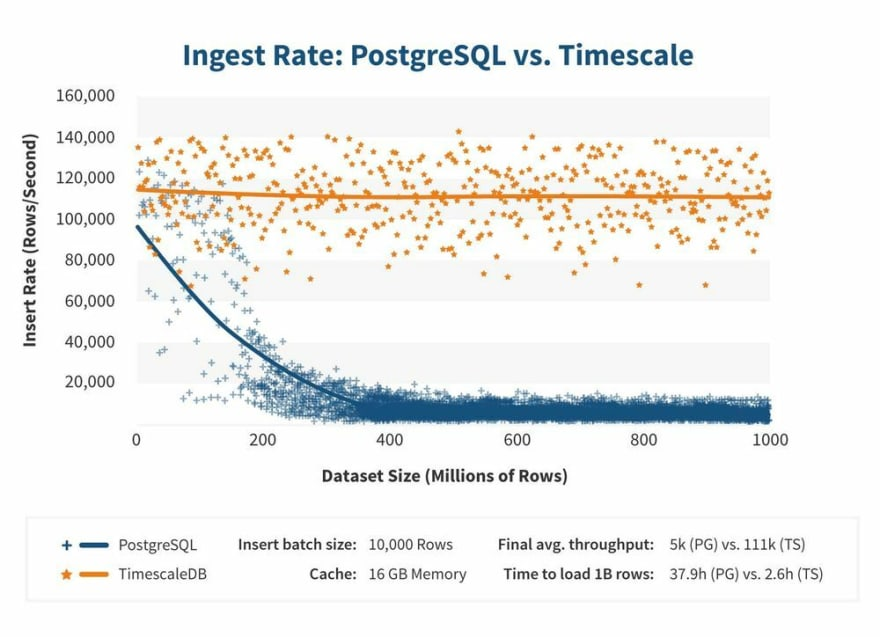
While PostgreSQL will be sufficient for our first few million rows, we will start to see its performance decline as the number of writes increases and our table grows. The main pain points we faced included:
- Reads and writes being too slow at scale
- Threat of growing table size causing disk pressure
- With these points in mind, we chose TimescaleDB.
What is TimescaleDB?
TimescaleDB is a time-series database built on top of PostgreSQL. It is an extension to PostgreSQL that implements tools to aide in the handling and processing of time-series data. The Timescale extension runs within a PostgreSQL server processing queries first to determine the planning and execution of queries involving time-series data. This enables much higher data ingestion rates and greatly improves query performance.
How we used Timescale to solve our problem
The first step taken was to convert the table storing our metrics into a Hypertable. Hypertables look and feel like regular PostgreSQL tables but are partitioned by Timescale into time based chunks. Creating a Hypertable allows us to take advantage of Timescale's full suite of tooling in addition to the ingestion and query performance.
The next step was to create a compression policy on the Hypertable. Timescale will compress chunks of data older than an interval you specify in a compression policy, in our case, 1 week. This data can still be accessed but not updated. Enabling compression on a Hypertable has between a 91-96% storage savings.
Finally, we used continuous aggregates. They are similar to PostgreSQL's materialized views but can be refreshed using a policy. We created a continuous aggregate that averages each stat over a 15 second interval refreshing every minute. This allows us to select already processed data from a smaller table, ready to be consumed by the front end.